|
Research Scientist at NAVER LABS Europe I was a doctoral researcher at NAVER LABS Europe and Inria Grenoble (the THOTH Team) in France, under the supervision of Yannis Kalantidis, Diane Larlus and Karteek Alahari. My PhD focused on learning general-purpose visual representations from images. I received my M.Sc. degree from the Computer Engineering Department at Bilkent University in Türkiye, where I worked with Gokberk Cinbis on learning data-efficient visual classification models. Before that, I received my B.Sc. from the Electrical and Electronics Engineering Department at Anadolu (now Eskisehir Technical) University in Türkiye. Email / CV / Google Scholar / Twitter / Github |

|
|
|
|
I'm broadly interested in computer vision problems. If I have to be more specific, I like working on learning visual representations from imagery data with different forms of supervision (including no supervision at all!) so that they are useful for a range of vision tasks. |
|
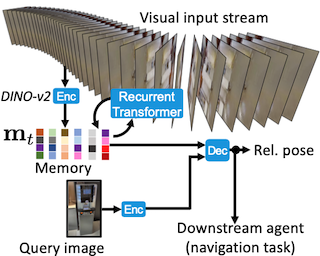
Mert Bulent Sariyildiz, Philippe Weinzaepfel, Guillaume Bono, Gianluca Monaci, Christian Wolf NeurIPS 2025
We introduce a new model, Kinaema, and agent, capable of integrating a stream of visual observations while moving in a potentially large scene, and upon request, processing a query image and predicting the relative position of the shown space with respect to its current position. |
|
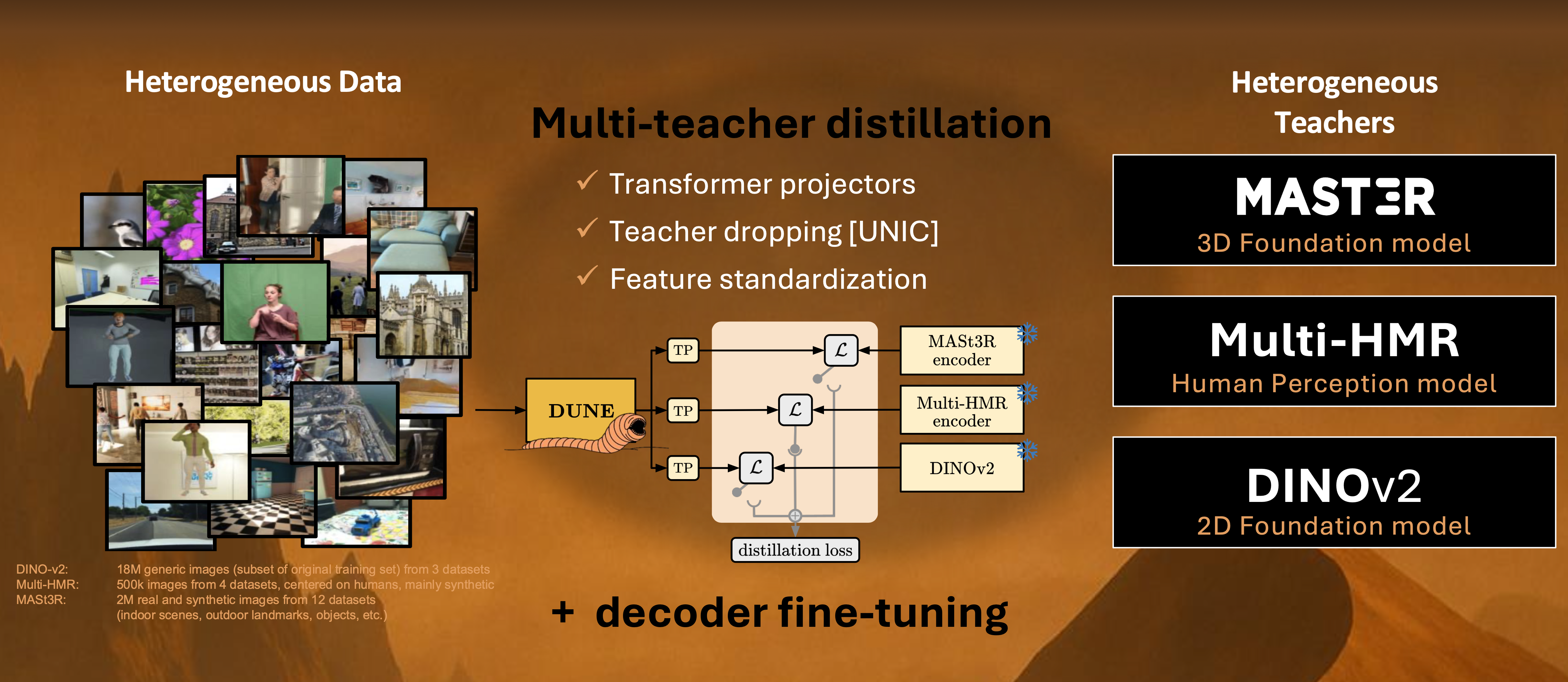
Mert Bulent Sariyildiz, Philippe Weinzaepfel, Thomas Lucas, Pau de Jorge, Diane Larlus, Yannis Kalantidis CVPR 2025
In this paper, we define and investigate the problem of heterogeneous teacher distillation, or co-distillation, a challenging multi-teacher distillation scenario where teacher models vary significantly in both (a) their design objectives and (b) the data they were trained on. |
|
Mert Bulent Sariyildiz, Philippe Weinzaepfel, Thomas Lucas, Diane Larlus, Yannis Kalantidis ECCV 2024
We distill multiple pretrained models into a single, unified encoder.
Beginning with an in-depth analysis of standard distillation techniques using multiple complementary teachers, we introduce a series of enhancements tailored for multi-teacher distillation.
Our approach produces student models that match the capacity of the original teachers while being equal to or surpassing the performance of the best teacher on each task. |

|
Yannis Kalantidis*, Mert Bulent Sariyildiz*, Rafael S. Rezende, Philippe Weinzaepfel, Diane Larlus and Gabriela Csurka ICLR 2024 Visual localization methods generally rely on a first image retrieval step whose role is crucial. In this paper, we improve this retrieval step and tailor it to the final localization task. We propose to synthesize variants of the training set images, obtained from generative text-to-image models, in order to automatically expand the training set towards a number of nameable variations that particularly hurt visual localization. |

|
Mert Bulent Sariyildiz, Karteek Alahari, Diane Larlus and Yannis Kalantidis CVPR 2023 Recent text-to-image generative models, generate fairly realistic images. Could such models render real images obsolete for training image prediction models? We answer part of this provocative question by questioning the need for real images when training models for ImageNet-1K classification. We show that models trained on synthetic images exhibit strong generalization properties and perform on par with models trained on real data. |

|
Mert Bulent Sariyildiz, Yannis Kalantidis, Karteek Alahari and Diane Larlus ICLR 2023
We revisit supervised learning on ImageNet-1K and propose a training setup which
improves transfer learning performance of supervised models. |
|
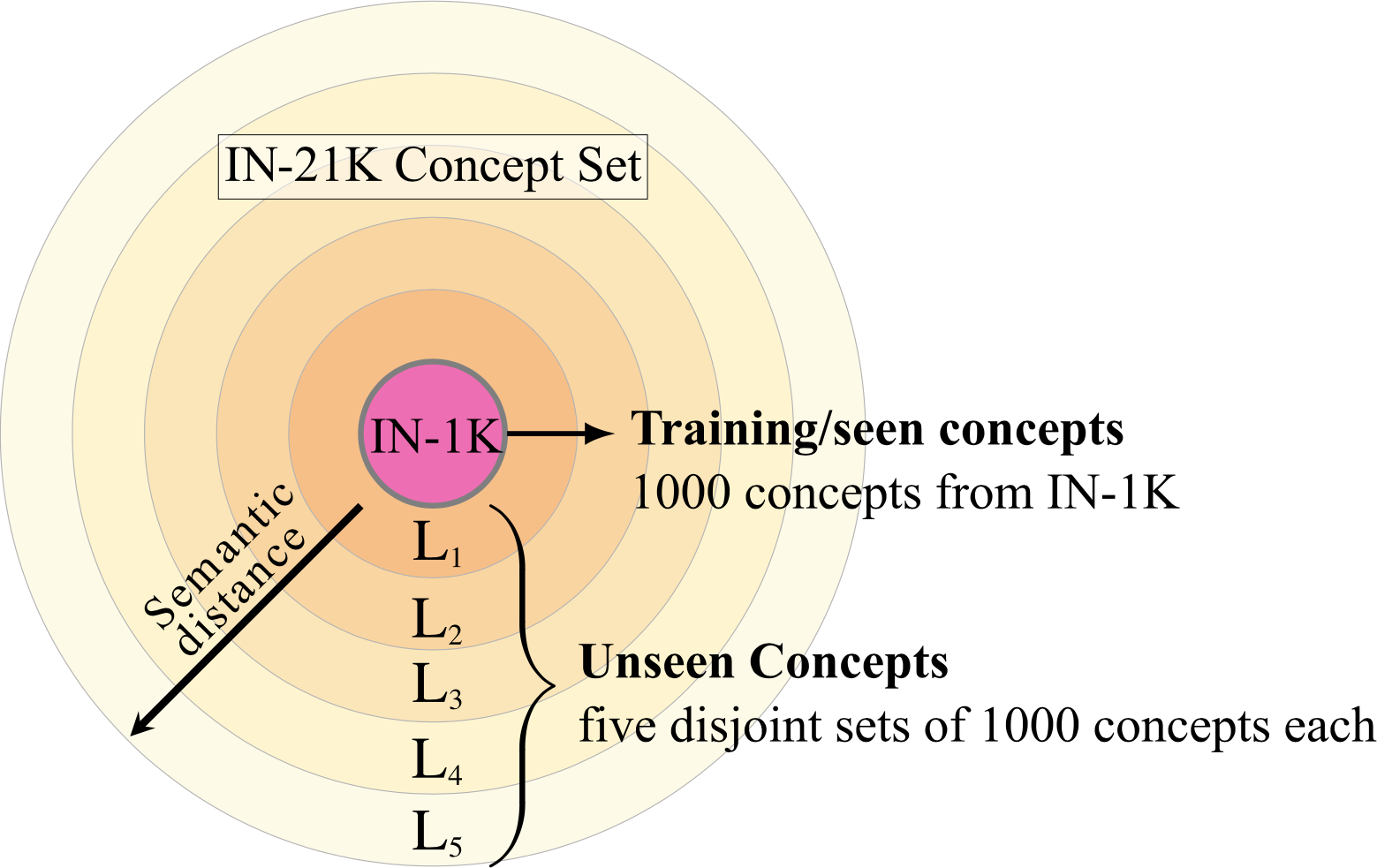
Mert Bulent Sariyildiz, Yannis Kalantidis, Diane Larlus and Karteek Alahari ICCV 2021
We propose a benchmark tailored for measuring concept generalization
capabilities of models trained on ImageNet-1K. |
|
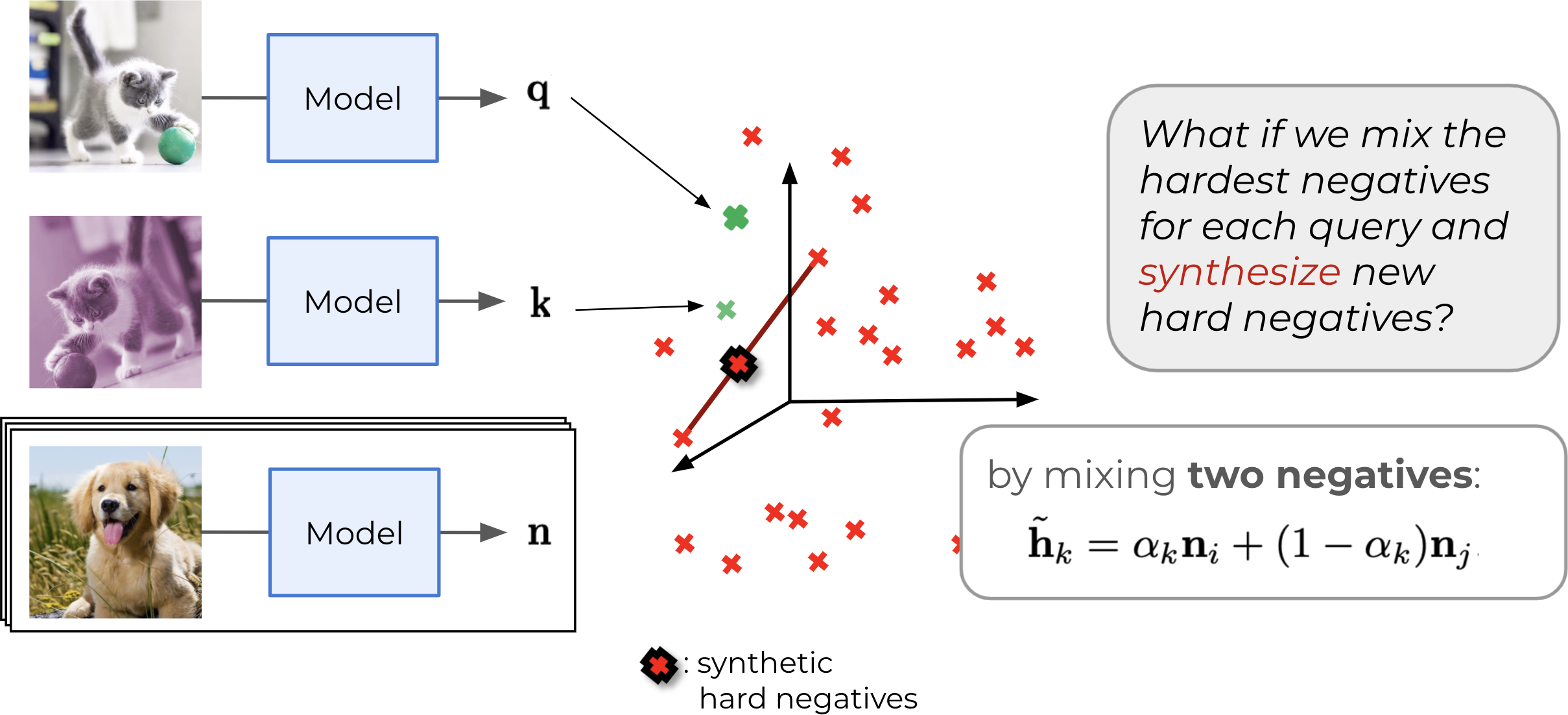
Yannis Kalantidis, Mert Bulent Sariyildiz, Noe Pion, Philippe Weinzaepfel and Diane Larlus NeurIPS 2020
For contrastive learning, sampling more or harder negatives often improve
performance.
We propose two ways to synthesize more negatives using the MoCo framework. |

|
Mert Bulent Sariyildiz, Julien Perez and Diane Larlus ECCV 2020
Images often come with accompanying text describing the scene in images.
We propose a method to learn visual representations using (image, caption)
pairs. |
|
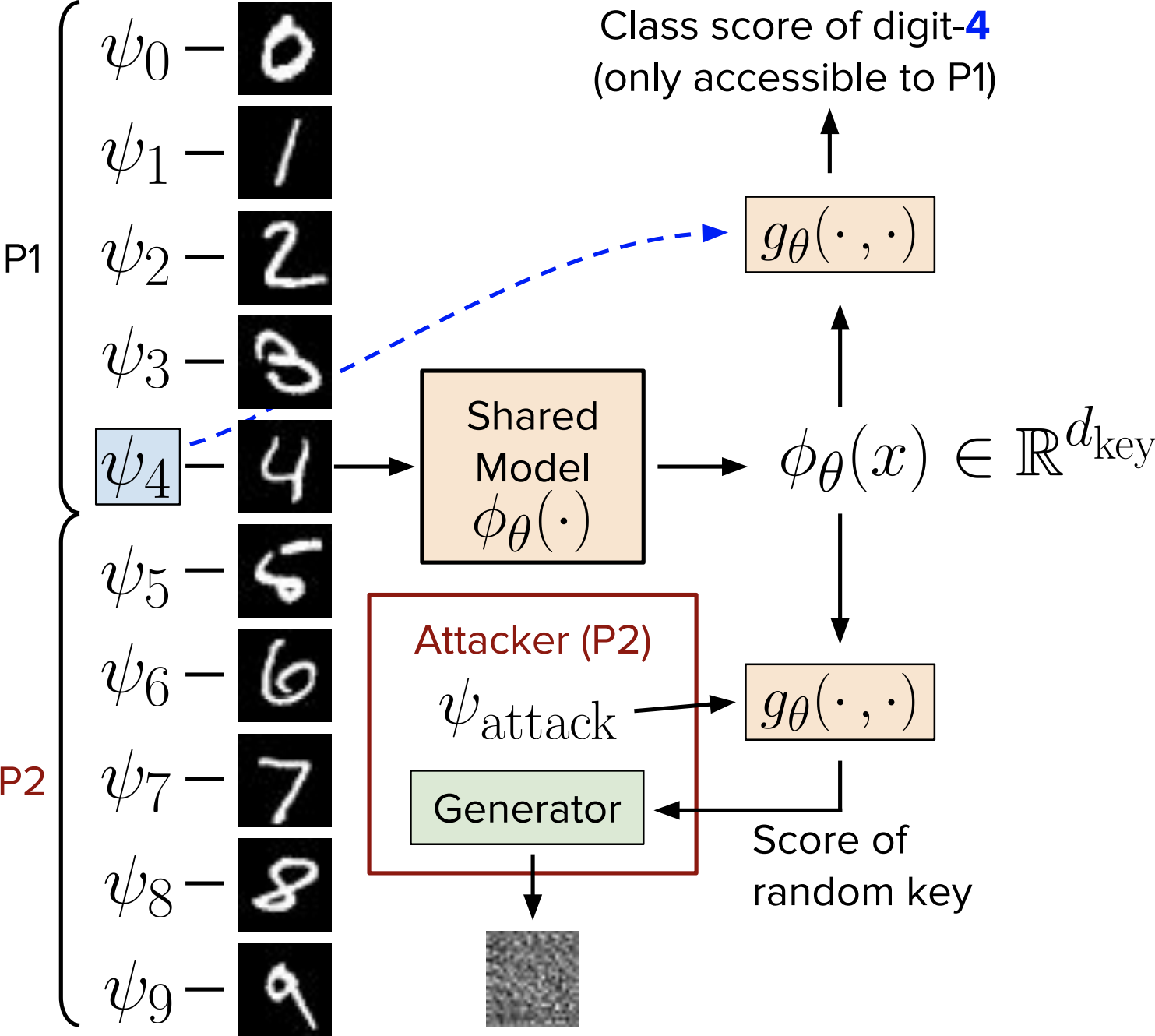
Mert Bulent Sariyildiz, Ramazan Gokberk Cinbis and Erman Ayday Pattern Recognition, Vol. 104, August 2020
Vanilla collaborative learning frameworks are vulnerable to an active adversary
that runs a generative adversarial network attack.
We propose a classification model that is resilient against such attacks by
design. |
|
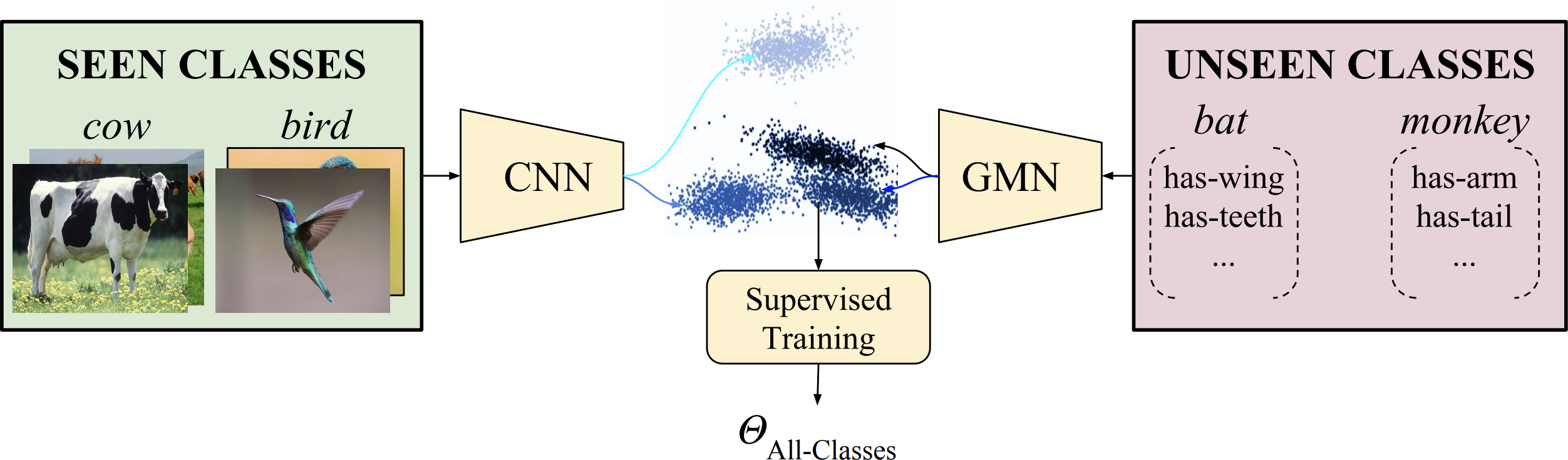
Mert Bulent Sariyildiz and Ramazan Gokberk Cinbis CVPR 2019, oral presentation
Zero-shot learning models may suffer from the domain-shift due to the difference
between data distributions of seen and unseen concepts.
We propose a generative model to synthesize samples for unseen concepts given
their visual attributes and use these samples for training a classifier for both
seen and unseen concepts. |
|
Huge thanks to Jon Barron, who provides the template of this website. |